一.TF serving实现
TF serving托管模型流程包括4个步骤:训练模型,导出模型,发布模型,更新线上模型服务。
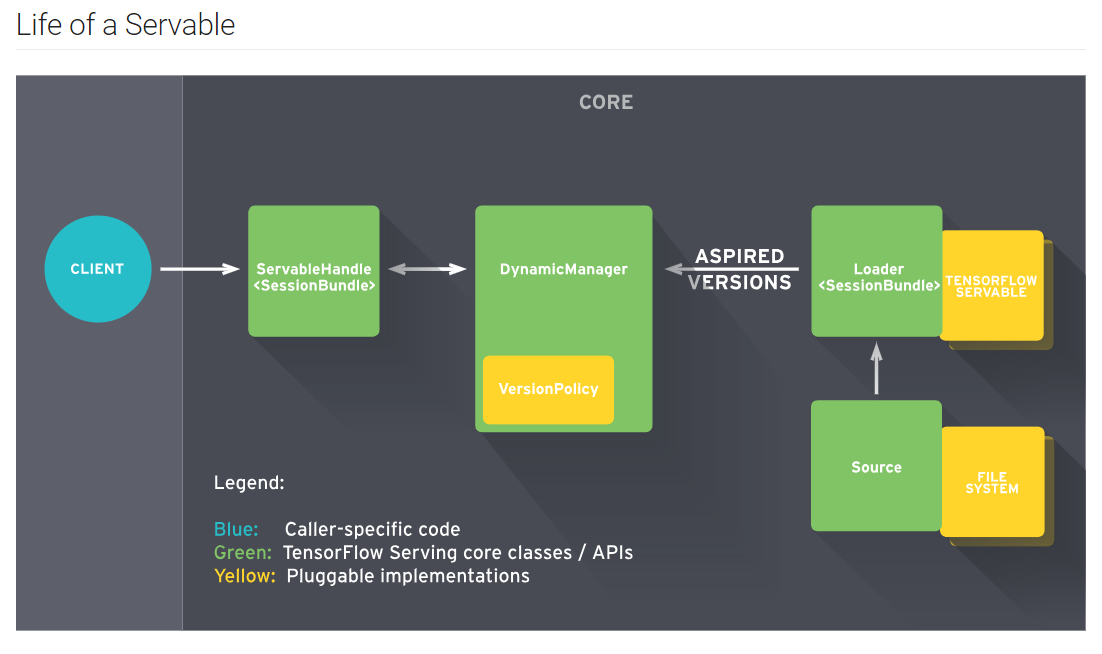
1.Servables
Servables 是 TensorFlow Serving 中最核心的抽象,是服务器端提供计算和查询服务的的实例对象。Servables 的大小和力度是灵活的,单个 Servable 可能包含从一个查找表的单个分片,到一个单独的模型,或是推理模型的元组。一套TF serving支持同时运行多个服务。
Servables 并不管理自身的生命周期。
典型的 Servables 包括:
- 一个 TensorFlow 的 SavedModelBundle (
tensorflow::Session) - 一个用于 Embedding 的查找表或词汇表
Servables Streams
一个 Servables Stream 是多个版本的 Servable 的序列,其按照版本号的递增排序。
2.Models
TensorFlow Serving 将一个 模型 (model) 表示为一个或多个 Servables。一个机器学习模型可能包括一个或多个算法 (包括学习到的权重) 和查找表。
可以将一个 复合模型 (composite model) 表示成如下形式:
- 多个独立的 Servables
- 一个组合的 Servables
一个 Servable 也可能是一个模型的一部分,例如,一个大的查找表可能被分割到多个不同的 TensorFlow Serving 实例中。
3.Loaders
Loaders 管理一个 Servable 的生命周期。Loaders 将一个 Servable 的加载和卸载的 API 进行了标准化,并且提供评估系统资源是否足够加载Servable的接口。
4.Sources
Sources 是数据处理器抽象,负责监控和处理Servable加载的数据,比如文件系统指定路径下的查找表文件或模型文件。TensorFlow Serving 中 Sources 的接口可以从任意的存储系统中发现 Servables,TesorFlow Serving 包含了 Source 实现的通用引用。例如:Sources 可以利用 RPC 等机制,并可以轮训文件系统。Sources 可以维护多个 Servables 或 不同版本分片中的状态,这将有助于 Servables 在不同版本之间进行 Delta (diff) 更新。
5.Managers
Managers 维护 Servables 的整个生命周期,包括:
- 加载 Servables
- 为 Servables 提供服务
- 卸载 Servables
Managers 从 Sources 获取信息并跟踪所有的 Versions。Manager 尽可能的满足 Sources 的请求,但当所需的资源不存在时,会拒绝载入一个 Aspired Versions。Manager 也可能延迟触发一个卸载 (unload),例如:基于要确保任意时点都要至少有一个 Version 被加载的策略,Manager 需要等待一个新的 Version 完成加载后再卸载之前的 Version。
6.SavedModel
是TF模型持久化存储的通用序列化格式,是打通从模型训练到服务发布流程的关键。在训练阶段,我们可能使用输入流水线和超参数优化操作。当模型发布为服务时,需要删除或替换这些操作,否则会出现推理准确率低,输入队列阻塞的情况。
为了提升服务发布后的准确率或其他评价指标,我们需要保存多分不同的数据流图进行测试。SavedModel支持用一份saved_model.pb文件来保存多幅不同的数据流图,这些数据流图可以共享模型参数和资源。
7.ServableHandle
是响应gPRC客户端访问请求的服务句柄,ServableHandle与已加载的Servable一一对应。客户端请求TF serving服务时,服务端ServableHandle会调用相应的Servable服务接口,并将相应返回给客户端。如果服务尚未加载,则向客户端返回错误信息。
8.Batch
将多个请求批处理为单个请求可以显著降低推理的成本,特别是在有 GPU 等加速器的情况下。TensorFlow Serving 包含了一个用于批处理请求的小工具,它允许客户端可以轻松的将请求中特定类型的推断合成一个批处理请求,以便系统能够更有效的处理。
在提供TensorFlow模型时,将单个模型推理请求一起批处理对于性能非常重要。特别是,批处理对于解锁GPU等硬件加速器所承诺的高吞吐量是必要的。这是一个用于批处理请求和调度批处理的库。该库本身并不依赖于GPU,并且可以用于串联处理小任务组的任何情况。 它提供了特定的TensorFlow会话API,以及可用于在其他粒度批处理的低级API。
该库目前分为:(1)core / kernels / batching_util(核心API和实现)(2)tensorflow_serving / batching(更高级别和实验代码)。
BatchingSession
BatchingSession将批处理添加到标准tensorflow :: Session,并允许您使用单个(非批处理)张量调用Session :: Run(),同时获得批量处理“隐藏”的好处。请求线程使得在等待其他组调用阻塞的Session :: Run(),调用进入同一个批处理。要使用此同步API实现良好的吞吐量,建议将客户端线程数设置为最大批量大小的两倍。
使用BatchingSession的最简单方法是通过CreateRetryingBasicBatchingSession(),它使用下面的BasicBatchSchedule提供了一个tensorflow :: Session对象,并且还处理溢出调度程序队列的重试请求。
Batch大小可以设置为1-1024。
BasicBatchScheduler
BasicBatchScheduler是一个比BatchingSession更低级的抽象,它与张量/ TensorFlow本身无关。它适用于处理同类请求的服务器。BasicBatchScheduler提供了一个异步API,称为BatchScheduler,该API由BatchTask类进行模板化,该类封装了要批处理的工作单元。 非阻塞Schedule()方法用于将任务排入队列以进行处理。 准备好处理一批任务后,将在单独的线程上调用回调来处理批处理
Mixed CPU/GPU/IO Workloads
除了主要的GPU工作之外,一些模型还执行非常重要的CPU工作。虽然核心矩阵操作可以在GPU上良好运行,但是外围操作可以在CPU上进行,例如,嵌入查找,词汇查找,量化/反量化。根据GPU的管理方式,将整个CPU和GPU步骤序列作为一个单元进行批处理可能无法充分利用GPU。
可以在请求线程中执行非GPU预处理和后处理,批处理调度程序仅用于工作的GPU部分。
或者,非GPU工作可以在批处理线程中完成,在批处理调度程序调用的回调中。要允许回调在完全形成批处理之前对任务执行非批处理工作,可以使用StreamingBatchScheduler。它专为非常精确控制延迟的服务器而设计,需要对流水线的每个阶段进行精细控制。
如果调度程序当前没有处理能力,StreamingBatchScheduler将拒绝任务。如果要自动重试因此原因而被拒绝的任务,可以在批处理调度程序之上对BatchSchedulerRetrier进行分层。有一个便利功能,用于创建与调度程序相结合的流调度程序:CreateRetryingStreamingBatchScheduler()。
将模型推理逻辑拆分为多个不同阶段以优化延迟或利用率时,请记住,对于给定请求,每个阶段都应使用相同版本的模型。确保此属性的一个好方法是协调跨线程在每个阶段使用哪个ServableHandle对象。
最后,I / O密集的推理阶段,例如查找磁盘或远程服务器可能会受益于批处理以隐藏其延迟。您可以使用两个批处理调度程序实例:一个用于批处理这些查找,另一个用于批处理GPU工作。
二. TF serving流程
1.训练和导出模型
TF服务器端组件只负责模型服务的发布和更新,模型导出由TF原生的tensorflow.saved_model.builder.SavedModelBuilder模块实现。SavedModelBuilder定期向文件系统中的目标路径导出模型快照,模型快照的格式为SavedModel序列化格式。对于 SavedModel 格式的详细信息,参见 SavedModel REAMDE.md 文档,如下代码片段说明了将模型保存至硬盘的一般流程。
1 | export_path_base = sys.argv[-1] |
每个版本子目录中包含如下文件:
saved_model.pb是序列化的tensorflow::SavedModel文件。其包含一个或多个计算图的定义,同时也包含模型的一些元信息,例如 Signatures。variables为一系列包含了计算图中的变量的序列化文件。
谷歌推荐的保存模型的方式是保存模型为 PB 文件,它具有语言独立性,可独立运行,封闭的序列化格式,任何语言都可以解析它,它允许其他语言和深度学习框架读取、继续训练和迁移 TensorFlow 的模型。它的主要使用场景是实现创建模型与使用模型的解耦, 使得前向推导 inference的代码统一。另外的好处是保存为 PB 文件时候,模型的变量都会变成固定的,导致模型的大小会大大减小,适合在手机端运行。
2.定义模型服务的参数和配置
使用SavedModelBuilder导出模型分为以下3步:
- 构造SavedModelBuilder实例,并设置模型的导出路径
- 定义模型服务的SignatureDef
- 使用SavedModelBuilder实例导出模型
创建SavedModelBuilder实例后,调用它的add_meta_graph_and_variables成员方法,添加期望导出的数据流图和模型参数。add_meta_graph_and_variables发放的主要输入参数包括:
sess为包含需要导出的训练好的模型的 TensorFlow 会话。tags数据流图的类型标签,可以选的取值包括SERVING,TRAINING和GPU。分别表示该数据流图用于提供服务,训练模型,以及使用GPU设备。signature_def_map指定了用于添加到 Meta Graph 中的从用户提供的键到tensorflow::SignatureDef之间的映射。Signature 指定了导出模型的类型,以及在进行推理阶段所绑定的输入和输出张量。
predict_signature签名配置(包括回归,分类,推理)
作为一个 predict_signature 定义的示例,工具函数接受如下参数:
inputs={'images': tensor_info_x}指定输入张量的信息。outputs={'scores': tensor_info_y}指定输出评分张量的信息。method_name表示用于推理的方法。对于预测请求,其应被设置为tensorflow/serving/predict,对于其他方法名称,参见 TensorFlow API 文档。
3.Serving with Docker using GPU
(1)Install nvidia-docker (下载)
Before serving with a GPU, in addition to installing Docker, you will need:
- Up-to-date NVIDIA drivers for your system
nvidia-docker: You can follow the installation instructions here
(2)Running a GPU serving image
Running a GPU serving image is identical to running a CPU image. For more details, see running a serving image.
(3)Serving GPU docker image
1 | docker pull tensorflow/serving:latest-gpu |
(4)指定GPU Docker加载模型
1 | docker run --runtime=nvidia -p 8501:8501 \ |
(5)服务运行在指定端口,通过网络请求调用服务
1 | 2019-01-11 00:07:20.773693: I tensorflow_serving/model_servers/main.cc:333] |
发送请求,调用服务
1 | curl -d '{"instances": [1.0, 2.0, 5.0]}' \ |
三.实验
实验环境
core i3 4核心 3.1GHZ
GTX 1050 4G显存
内存 4GB
测量参数
1.CPU利用率,CPU负载
2.内存占用
3.GPU显存占用,GPU利用率
1. 多用户依次请求
10000个用户请求陆续到达,服务器依次响应每个用户请求。
用户请求相同
每次用户请求的模型和输入数据都相同
用户请求不同
每次用户请求的模型和输入数据都相同
2. 多用户按批次请求
10000个用户请求按批次加载到服务器,服务器按批次执行用户请求。
Batching can be turned on by providing proper SessionBundleConfig when creating the SavedModelBundleSourceAdapter. In this case we set the BatchingParameters with pretty much default values. Batching can be fine-tuned by setting custom timeout, batch_size, etc. values. For details, please refer to BatchingParameters.
1 | SessionBundleConfig session_bundle_config; |
在到达完整批处理时,推理请求在内部合并为单个大请求(张量),并调用tensorflow :: Session :: Run()(这是GPU上实际效率增益的来源)
3.模型训练(对比)
10000个epochs训练过程

四.模型分析
1. 神经网络显存占用
神经网络模型占用的显存包括:
- 模型自身的参数
- 模型的输出
举例来说,对于如下图所示的一个全连接网络(不考虑偏置项b)
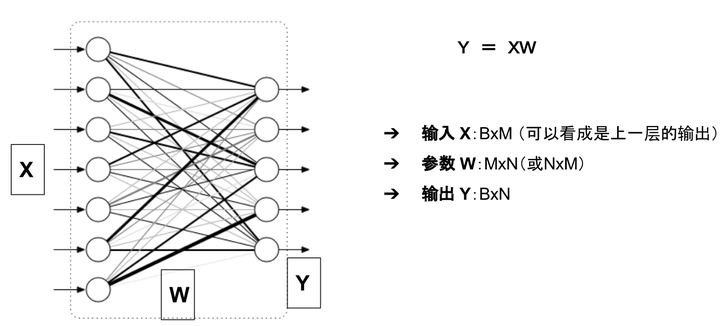
模型的显存占用包括:
参数:二维数组 W
模型的输出: 二维数组 Y
输入X可以看成是上一层的输出,因此把它的显存占用归于上一层。
1.2 参数的显存占用
只有有参数的层,才会有显存占用。这部份的显存占用和输入无关,模型加载完成之后就会占用。
有参数的层主要包括:
- 卷积
- 全连接
- BatchNorm
- Embedding层
- … …
无参数的层:
- 多数的激活层(Sigmoid/ReLU)
- 池化层
- Dropout
- … …
更具体的来说,模型的参数数目(这里均不考虑偏置项b)为:
- Linear(M->N): 参数数目:M×N
- Conv2d(Cin, Cout, K): 参数数目:Cin × Cout × K × K
- BatchNorm(N): 参数数目: 2N
- Embedding(N,W): 参数数目: N × W
参数占用显存 = 参数数目×n
n = 4 :float32
n = 2 : float16
n = 8 : double64
在PyTorch中,当你执行完model=MyGreatModel().cuda()之后就会占用相应的显存,占用的显存大小基本与上述分析的显存差不多(会稍大一些,因为其它开销)。
1.3 梯度与动量的显存占用
举例来说, 优化器如果是SGD:
可以看出来,除了保存W之外还要保存对应的梯度 ,因此显存占用等于参数占用的显存x2,
如果是带Momentum-SGD
这时候还需要保存动量, 因此显存x3
如果是Adam优化器,动量占用的显存更多,显存x4
总结一下,模型中与输入无关的显存占用包括:
- 参数 W
- 梯度 dW(一般与参数一样)
- 优化器的动量(普通SGD没有动量,momentum-SGD动量与梯度一样,Adam优化器动量的数量是梯度的两倍)
1.4 输入输出的显存占用
这部份的显存主要看输出的feature map 的形状。
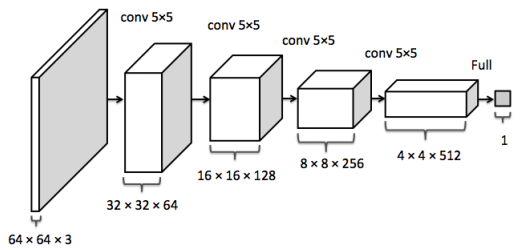 feature map
feature map
比如卷积的输入输出满足以下关系:
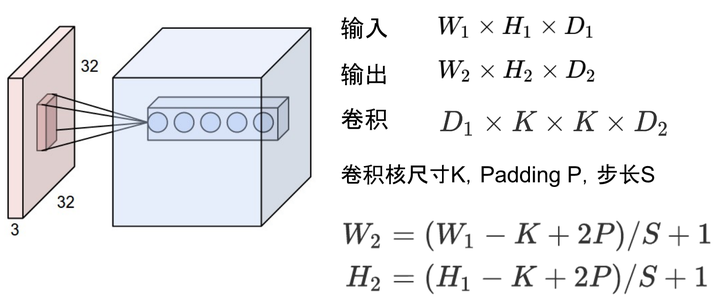
据此可以计算出每一层输出的Tensor的形状,然后就能计算出相应的显存占用。
模型输出的显存占用,总结如下:
- 需要计算每一层的feature map的形状(多维数组的形状)
- 需要保存输出对应的梯度用以反向传播(链式法则)
- 显存占用与 batch size 成正比
- 模型输出不需要存储相应的动量信息。
深度学习中神经网络的显存占用,我们可以得到如下公式:
1 | 显存占用 = 模型显存占用 + batch_size × 每个样本的显存占用 |
可以看出显存不是和batch-size简单的成正比,尤其是模型自身比较复杂的情况下:比如全连接很大,Embedding层很大
另外需要注意:
- 输入(数据,图片)一般不需要计算梯度
- 神经网络的每一层输入输出都需要保存下来,用来反向传播,但是在某些特殊的情况下,我们可以不要保存输入。比如ReLU,在PyTorch中,使用
nn.ReLU(inplace = True)能将激活函数ReLU的输出直接覆盖保存于模型的输入之中,节省不少显存。




