一.TensorRT介绍
TensorRT项目立项的时候名字叫做GPU Inference Engine(简称GIE),Tensor表示数据流动以张量的形式,RT表示的是Runtime。下图是TensorRT的架构图。TensorRT是英伟达公司出品的高性能的推断C++库,专门应用于边缘设备的推断,TensorRT可以将我们训练好的模型分解再进行融合,融合后的模型具有高度的集合度。我们平时所见到了深度学习落地技术:模型量化、动态内存优化以及其他的一些优化技术TensorRT都已经有实现,更主要的,其推断代码是直接利用cuda语言在显卡上运行的,所有的代码库仅仅包括C++和cuda,当然也有python的包装,在利用这个优化库运行训练好的代码,运行速度和所占内存的大小都会大大缩减。
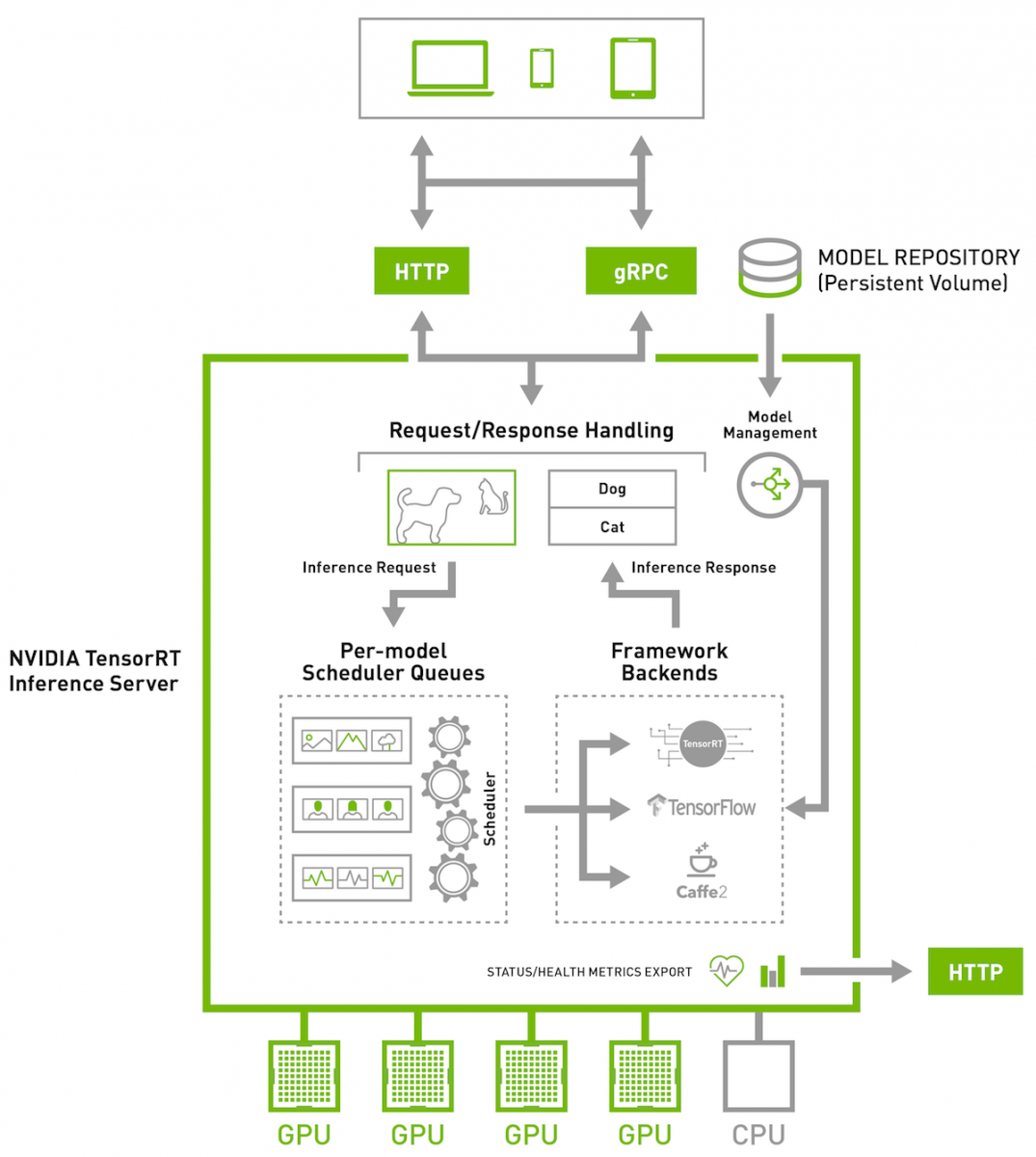
1.训练和推断
深度学习分为训练和部署两部分。训练部分首先构建网络结构,准备数据集,使用各种模型进行训练,训练包含validation和test的过程。训练的操作一般在线下,实时数据在线训练的情况比较少,大多数情况下数据是离线的,数据更新不频繁。线下有大规模的集群对数据或模型进行更新,训练需要消耗大量的GPU,batch size较大,一般训练模型batch size是128,甚至极端的1024,大的batch可以充分的利用GPU设备,实时性要求相对较低。
推断(Inference)的时候只需前向计算,将输入通过神经网络得出预测的结果。而推断(Inference)的实际部署可能部署在云端数据中心,比如手机语音输入,声音是传到云端处理好之后把数据返回;还可能部署在嵌入式的摄像头、无人机、机器人或车载的自动驾驶主机上。推断的特点是对实时性要求很高。语音识别对latency非常敏感,要能非常快的给出推断结果。模型如果做得不好,没有优化,可能需要二三百毫秒才能做完一次推断,加上来回网络传输,用户可能一秒后才能得到结果,对于语音识别和自动驾驶影响是非常大的。
2.推断应用
在部署阶段,latency是非常重要指标,TensorRT是专门针对部署进行优化的,目前TensorRT支持大部分主流的深度学习应用,除了CNN(卷积神经网络)领域,TensorRT 3.0支持RNN。
最典型的应用是图片分类,图片的语义分割、目标检测等都是以图片分类网络为基础进行改进的。目标检测训练是对已经打好框的图片进行前向计算,得出的框和实际的框(ground truth)进行对比,然后再做后向更新,更新模型。推断的时候,是一个摄像头实时拍摄图片并进行目标检测,摄像头每秒拍摄25-30帧图片,鉴于实际应用可能是二十路摄像头同时传输进来的数据,必须保证一块卡做到实时处理。
3.推断和训练区别
- 推断的网络权值已经固定,无后向传播过程,因此
模型固定,可以对计算图进行优化
输入输出大小固定,可以做memory优化
推断的batch size要小很多,因为如果batch size很大,吞吐可以很大,可以很好地利用GPU,但是推断latency会增加。
推断可以使用低精度技术,训练的时候因为要保证前后向传播,每次梯度的更新是很微小的,需要相对较高的精度,一般需要float型,如FP32位的浮点型来处理数据。但是推断对精度的要求没有那么高,研究表明可以用半长的float型,即FP16,也可以用8位的整型(INT8)来做推断。研究结果表明没有特别大的精度损失,尤其对CNN。对Binary(二进制)的使用也处在研究过程中,即权值只有0和1。低精度计算的好处是一方面可以减少计算量,原来计算32位的单元处理FP16的时候,理论上可以达到两倍的速度,处理INT8的时候理论上可以达到四倍的速度。另一方面是模型需要的空间减少,不管是权值的存储还是中间值的存储。
4.TensorRT的效果
使用GPU卡V100,V100有专门针对深度学习优化的TensorCore,TensorCore可以完成4×4矩阵的半精度乘法,(一个4×4的FP16矩阵和另外一个4×4的FP16矩阵相乘,当然可以再加一个矩阵(FP16 或FP32),得到一个FP32或者FP16的矩阵),TensorCore在V100上理论峰值可以达到120 Tflops。
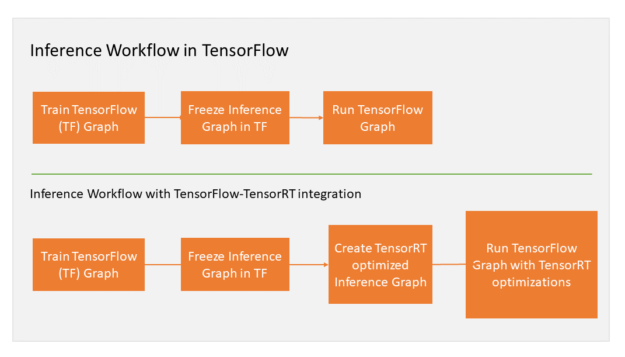
如图所示,如果只是用CPU来做推断,它的吞吐只能达到140,每秒只能处理140张图片,同时整个处理过程需要有14ms的延迟,也就是说用户提交请求后,推断阶段最快需要14ms才能返回结果;如果使用V100,在TensorFlow中去做推断,大概是6.67ms的延时,但是吞吐只能达到305;如果使用V100加TensorRT,在保证延迟不变的情况下,吞吐可以提高15倍,高达5700张图片每秒,这个差别是很大的。
NVIDIA TensorRT通过针对基于GPU的平台的优化和高性能运行时,加速所有框架(包括TensorFlow)的深度学习推理。ResNet-50模型在7毫秒延迟下的吞吐量提高了8倍。
二.TensorRT进行的优化
TensorFlow在实现神经网络的过程中可以使用各种各样的高级库,如用nn来搭建,tf.nn中的convolution中可以加一个卷积,可以用slim来实现卷积,不同的卷积实现效果不同,但是对计算图和GPU都没有做优化,甚至在中间卷积算法的选择上也没有做优化,而TensorRT在这方面做了很多工作。
1.TensorRT流程
TensorRT的流程, 首先输入是一个预先训练好的FP32的模型和网络,将模型通过parser等方式输入到TensorRT中,TensorRT可以生成一个Serialization,也就是说将输入串流到内存或文件中。模型解析后,engine会进行优化。得到优化好的engine可以序列化到内存(buffer)或文件(file),读的时候需要反序列化,将其变成engine以供使用。然后在执行的时候创建context,主要是分配预先的资源,engine加context就可以做推断。
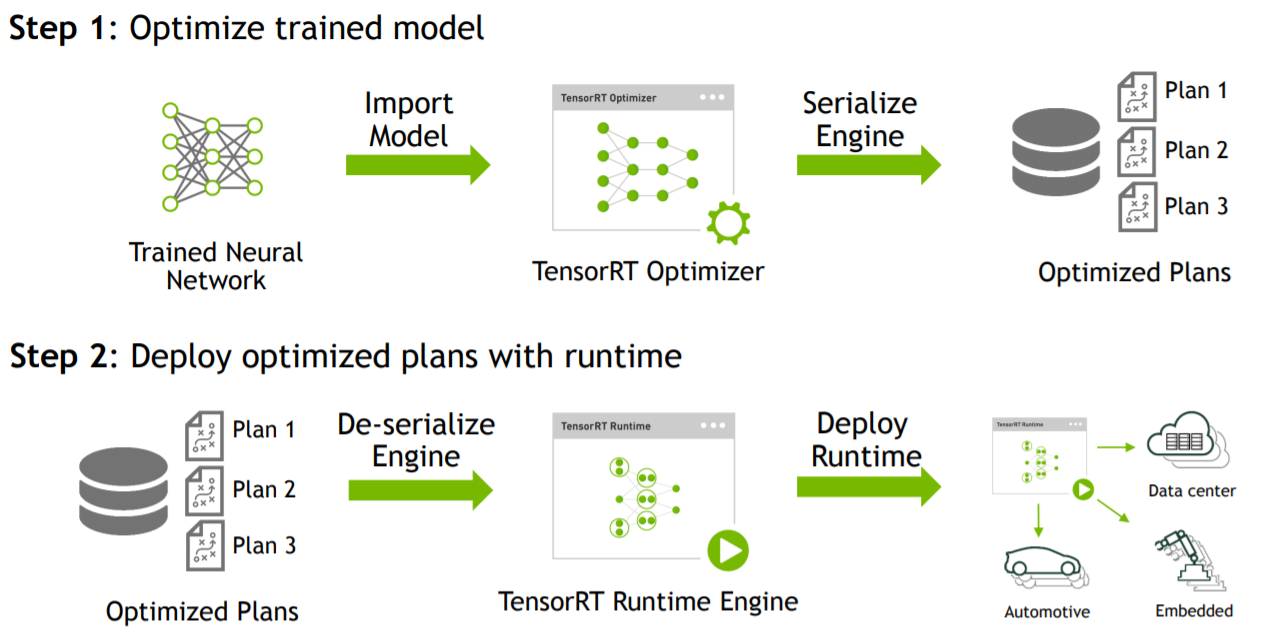
如图所示,TensorRT整个过程可以分三个步骤,即模型的解析(Parser),Engine优化和执行(Execution)。
一个深度学习模型的前向过程,包括:
1) 首先实现神经网络的layer,如卷积,pooling的实现。
2) 管理memory,数据在各层之间如何流动。
3) 推断的engine来调用各层的实现。
以上三个步骤在TendorRT都已经实现好了,用户需要做的是如何将网络输入到TensorRT中。目前TensorRT支持两种输入方式:
Parser的方式(即模型解析器),输入一个TF的模型,可以通过API解析出其中的网络层及网络层之间的连接关系,然后将其输入到TensorRT中。
API接口可以添加一个convolution或pooling操作。Parser解析模型文件,比如TensorFlow转换成的uff文件,再用API添加到TensorRT中,构建好网络并进行优化。
a) TensorRT只支持主流的操作,如果有一个网络层不支持,TensorRT是不知道是做什么的。可以构建用户自定义层需要告诉TensorRT该层的连接关系和实现方式。
b) 目前API支持C++和Python,Python接口实现比较方便。
c) Parser目前有三个,一个是caffe Parser,支持最完善;另一个是uff,这个是Nvidia定义的一种网络模型文件结构,现在TensorFlow可以直接转成uff;3.5或4.0版本支持的onnx,是Facebook主导的开源、可交换的网络模型文件结构,这个格式目前只在NGC (NVDIA GPU Cloud)上支持,但是下一个版本都会支持。
2.TensorRT所做优化

TensorRT把一些网络层进行了合并。在GPU上跑的函数叫Kernel,TensorRT可以对Kernel进行调用。在绝大部分框架中,比如convolution、bias和ReLU层,这三层需要调用三次cuDNN对应的API,但实际上这三层的实现完全是可以合并到一起,TensorRT会对一些可以合并网络进行合并。另外网络可能并行做若干个相同大小的卷积,这些卷积计算其实也是可以合并到一起,包括垂直层融合和水平层融合。
消除未使用的输出的层以避免不必要的计算:比如concat这一层,一边计算出来一个1×3×24×24,另一边计算出来1×5×24×24,concat到一起,变成一个1×8×24×24的矩阵。但concat这层这其实是完全没有必要的,因为TensorRT可以把矩阵直接接到需要的地方,不用专门做concat操作,所以这一层可以取消。
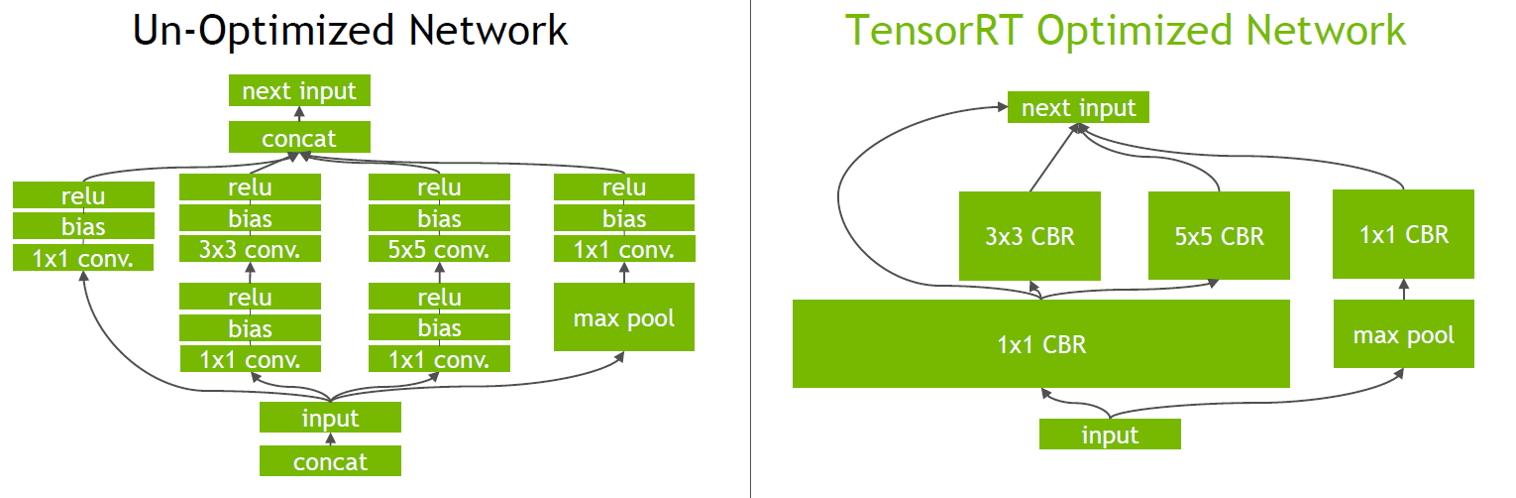
convolution, Bias和ReLU这三个操作可以合并成CBR,合并后的结果如图所示,其中包含四个1×1的CBR,一个3×3的CBR和一个5×5的CBR。接下来可以继续合并三个相连的1×1的CBR为一个大的1×1的CBR,这个合并就可以更好地利用GPU。接着concat层可以消除掉,直接连接到下一层的next input。另外还可以做并发(Concurrency),如图右半部分(max pool和1×1 CBR)与左半部分(大的1×1 CBR,3×3 CBR和5×5 CBR)是相互独立的两条路径,本质上是不相关的,可以在GPU上通过并发来达到的优化的目标。
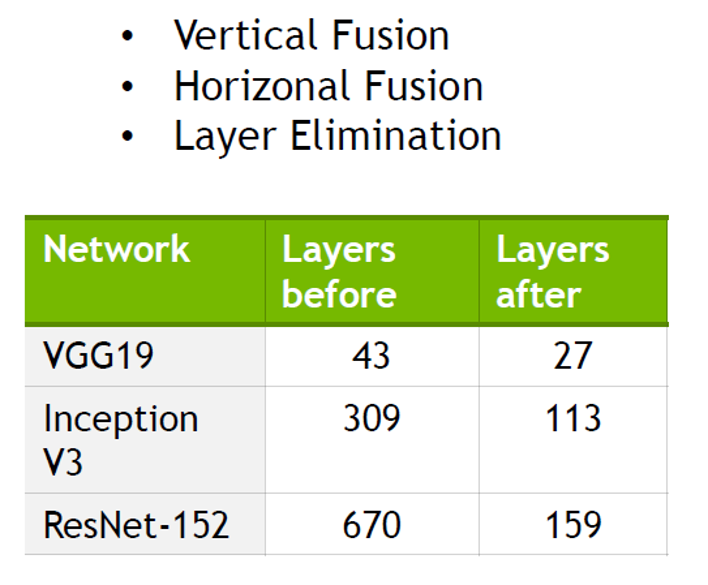
如图所示,效果是很好的。
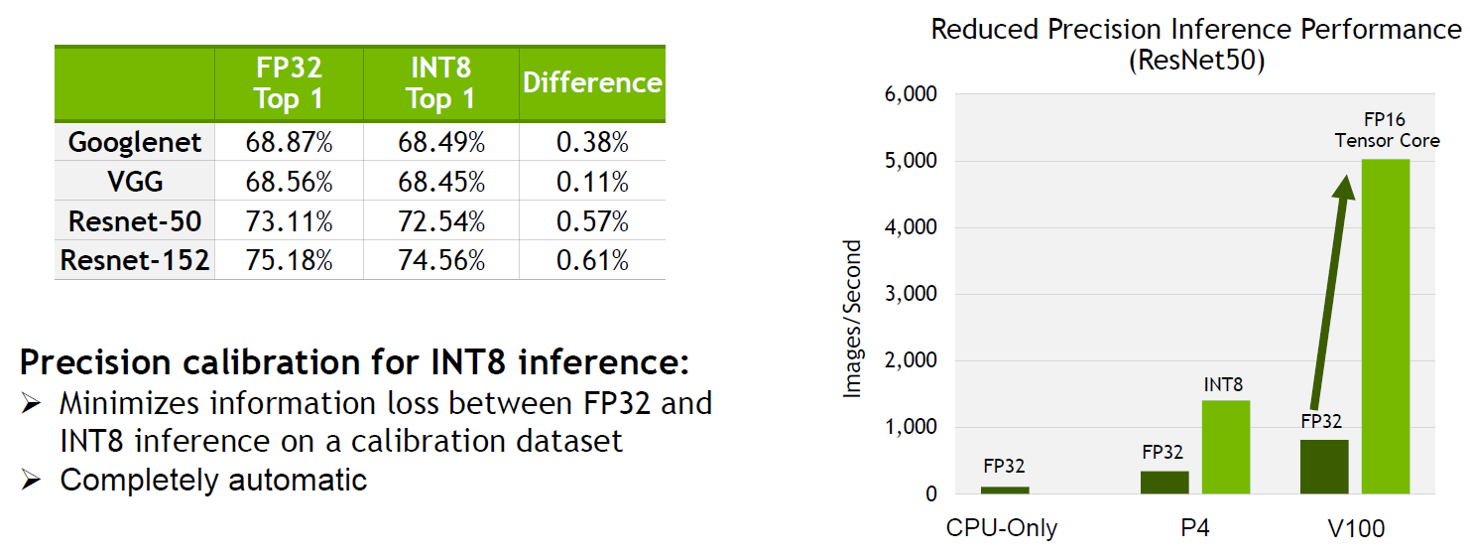
FP16和INT8降低精度,并进行校准:通过降低权重和激活精度,将模型量化为INT8来最大化吞吐量,同时保持准确性。
- 大多数深度学习框架以32位精度(FP32)训练神经网络。
•一旦模型完全训练,推理计算可以使用半精度FP16甚至INT8张量操作,因为推理不需要梯度反向传播。
•使用较低的精度可以缩小模型尺寸,降低内存利用率和延迟,并提高吞吐量。
•TensorRT可以在FP32,FP16和INT8中部署模型 - 为了将全精度信息量化为INT8,同时最大限度地降低精度损失,TensorRT必须执行一个校准的过程,以确定如何最好地将权重和激活表示为8位整数。
•校准步骤要求向TensorRT提供输入训练数据的代表性样本。
•无需对模型进行额外的微调或重新训练,也无需访问整个训练数据集。
•校准是一种完全自动化且无参数的方法,用于将FP32转换为INT8。
- 大多数深度学习框架以32位精度(FP32)训练神经网络。
Kernel可以根据不同的batch size 大小和问题的复杂程度,以及所使用的GPU,去选择最合适的算法,TensorRT预先写了很多GPU Kernel实现,可以进行自动选择。
在优化阶段,TensorRT还从数百个专用内核中进行选择,其中许多内核针对一系列参数和目标平台进行了手动调整和优化。
•例如,有几种不同的算法可以进行卷积。
•TensorRT将从内核库中选择实现,这些内核库可为目标GPU提供最佳性能,输入数据大小,过滤器大小,张量布局,批量大小和其他参数。
•这可确保部署的模型针对特定部署平台以及正在部署的特定神经网络进行性能调整。
动态内存优化:TensorRT通过仅在其使用期间为每个张量分配内存来减少内存占用并改善内存重用,从而避免内存分配开销以实现快速高效的执行。
多流执行:通过使用相同的模型和权重并行处理它们,可以扩展到多个输入流