Taskonomy: Disentangling Task Transfer Learning
摘要
这篇论文是计算机视觉顶会 CVPR 2018 最佳论文奖的文章:Taskonomy: Disentangling Task Transfer Learning。文章作者团队来自斯坦福大学和加州大学伯克利分校。文章的主题是探索任务迁移学习,通过做大量的实验,来揭示任务迁移学习中的一些现象。
人类的视觉具备多种多样的能力,计算机视觉届基于此定义了许多不同的视觉任务。长远来看,计算机视觉着眼于解决大多数甚至所有视觉任务,但现有方法大多尝试将视觉任务逐一击破。这种方法造成了两个问题:第一, 逐一击破需要为每一项任务收集大量数据,随着任务数量的增多,这将会是不可行的;第二,逐一击破会带来不同任务之间的冗余计算和重复学习。总的来说,逐一击破的策略忽略了视觉任务之间的关联性,比如法线 (Surface Normals) 是由深度 (Depth) 求导得来,语义分割 (Semantic Segmentation) 又似乎和遮挡边缘测试 (Occlusion edge detection) 有着千丝万缕的关联。基于上述两个问题,我们希望能有效测量并利用视觉任务之间的关联来避免重复学习,从而用更少的数据学习我们感兴趣的一组任务。
Taskonomy是一项量化不同视觉任务之间关联、并利用这些关联来最优化学习策略的研究。如果两个视觉任务A、B具有关联性,那么在任务A中习得的representations理应可为解决任务B提供有效的统计信息 。由此我们通过迁移学习计算了26个不同视觉任务之间的一阶以及高阶关联。如图一,如果有预测法线的网络和预测遮挡边缘测试的网络,我们可以通过结合两个网络的representations来快速通过少量数据解决Reshading和点匹配 (Point matching)。基于这些关联,我们利用0-1整数规划 (Binary Integer Programming) 求得一组我们感兴趣的任务,如何去最优分配训练数据量。 比如,如果想最高效地解决10个问题,利用Taskonomy提供的学习策略可以减少2/3的训练数据量。
正文
文章的方法概括起来就叫做 Taskonomy (Task taxonomy),这是一个计算图,它定义了任务之间的可迁移性。图中的节点表示任务,节点之间的边就表示迁移性,边的权重表示从一个任务迁移到另一个任务的可能表现。这个方法是文章的核心。它一共由下图所示的 4 个步骤构成。这 4 个步骤从逻辑上非常好理解。首先我们要对不同任务进行建模,然后让它们两两之间进行迁移并获取迁移的表现。接着为了构建一个统一的字典,我们对这些迁移结果进行归一化。最后,我们构建可迁移图。在迁移实验开始前,最重要的是,需要一个可用的超大型数据集,要包含不同的任务。然而目前没有。怎么办?很简单,作者构建了一个!这个数据集有从 600 个建筑物内拍摄的 400 万张图片。每张图片都针对不同的任务做了标注,也就是说都适用于每个任务。
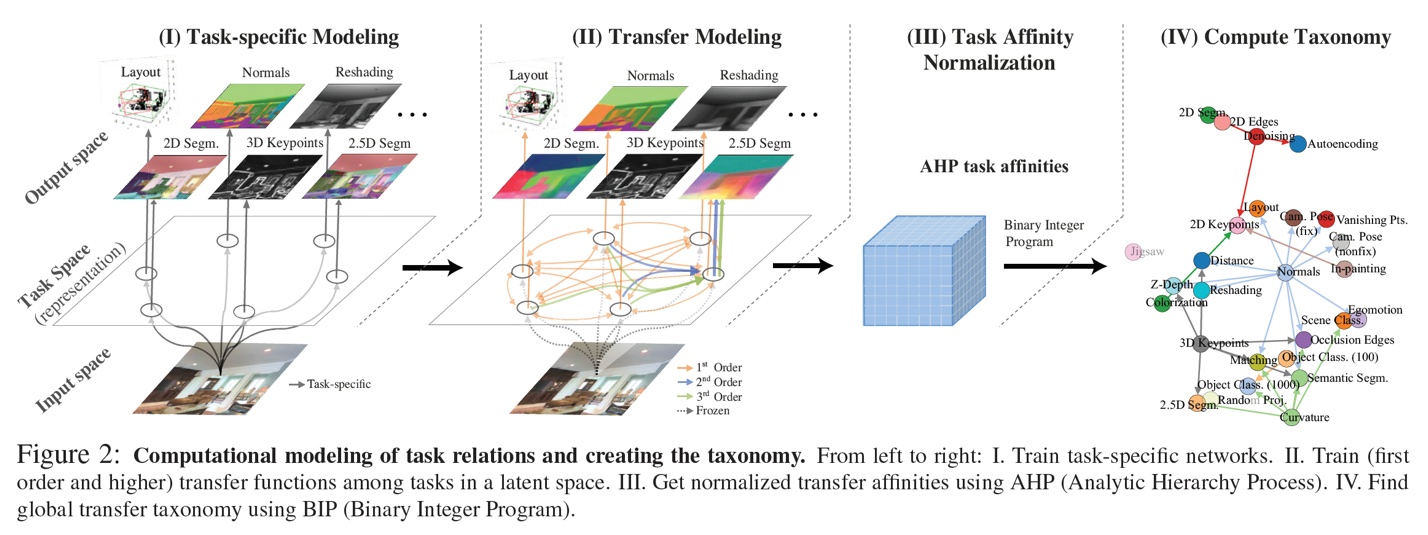
1.问题定义
首先,定义要解决的问题。我们想在有限的监督预算 下最大化在一组目标任务
上的表现。同时,我们有一组起始任务
,其定义为我们可从零学习的任务。监督预算
的定义为多少起始任务我们愿意从零开始学习(从零开始学习需要收集大量数据,监督预算表达了我们所面对的金钱、计算力和时间上的限制)。那么,
代表了我们感兴趣但不能从零学习的任务,比如一个只能有少量数据的任务。
代表了我们不感兴趣但可以从零学习(来帮助我们更好的学习
)的任务,如jigsaw、colorization等自我监督的视觉任务。
代表了我们感兴趣也能从零学习的任务,但因为从零学习会消耗监督预算,我们希望从中选择出符合预算的一组从零学习,余下的通过少量数据的迁移学习来实现。我们称
为我们的任务词典 (task dictionary)。最后,我们对视觉任务
的定义为一个基于图片的方程
。
如下图所示,收集了一个有四百万张图片的数据,每张图片均有26个不同视觉任务的标注(ground truth)。这26个任务涵盖了2D的、3D的和语义的任务,构成了本项research的任务词典。因为这26个任务均有标答, 也为这26个任务。

下面,进入第一大阶段,量化视觉任务的关联。
2.第一步:从零学习
对于每个起始任务, 我们为其从零开始学习一个神经网络。为了能更好地控制变量从而比较任务关联,每个任务的神经网络具有相似的encoder decoder结构。所有的encoder都是相同的类ResNet 50结构。因为每个任务的output维度各不相同,decoder的结构对不同的任务各不相同,但都只有几层,远小于encoder的大小。
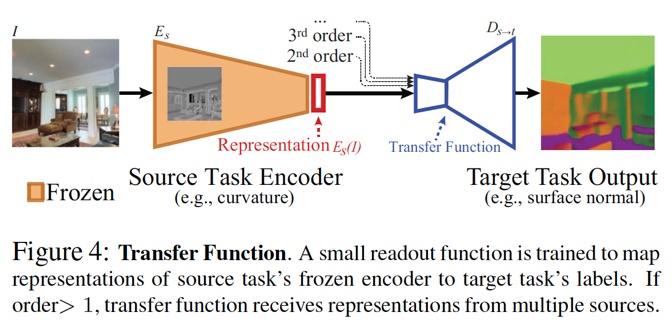
3.第二步:迁移学习
如上图所示,对于一个起始任务 和一个目标任务
,我们将以
的representation作为输入来学习
。我们将freeze任务
的encoder 参数,并基于encoder的输出 (representations) 学习一个浅层神经网络read out function。严谨来讲,如果我们用
表示
的encoder,
表示
的标注,
表示
的loss函数,
来表示图片和迁移训练集,
表示要迁移学习的浅层神经网络,学习目标为:
对于所有 和
组合,我们均训练了一个
。如下图所示,对于
,不同的
会对
的表现造成不同的影响。更具关联的
会为
提供更有效的统计信息,从而仅用1/60的训练数据(相较于从零学习)就能取得不错的结果;相反不具备关联的
则并不能有此表现。因此,我们认为
在
任务中的表现可以很好地代表了
之于
的关联性。
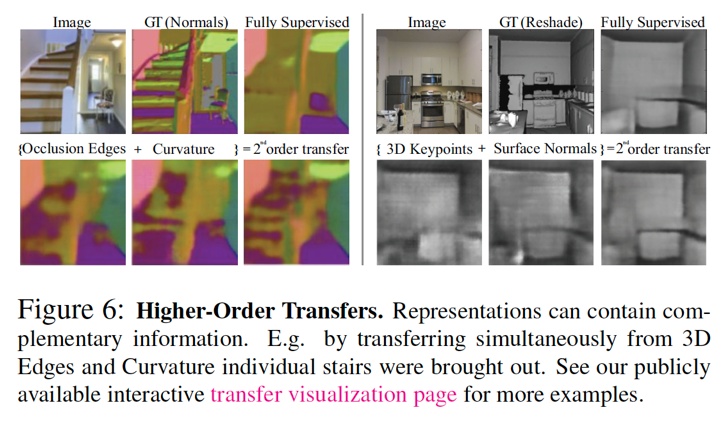
上述迁移代表了任务之间一对一的关联,我们称其为一阶关联。如下图,几个任务之间可能具有互补性,结合几个起始任务的representations会对解决目标任务起到帮助。因此,我们也研究了任务之间多对一的关联,我们称其问高阶关联。在这种情况下,我们将几个起始任务的representation结合起来当作目标任务的输入,其余细节跟上段类似。
因为高阶的任务组合数量太大,我们基于一阶表现选择了一部分的组合进行迁移学习。对于小于五阶的高阶,我们根据一阶的表现,将前五的所有组合作为输入。对于n>5阶,我们选择结合一阶表现前n的起始任务作为输入。
4.第三步:任务相似性标准化
这一步的目标很明确,就是构建一个迁移学习的相似度矩阵,从中我们可以很清楚地知道哪两个任务迁移效果最好。如何构建?我们本能地想到,可以把上一步中训练的损失函数拿来用。然而,不同任务下的损失函数不具有可比性,因此不能用。自然地,我们又想到了归一化,把所有的结果归一化到 [0,1] 之间。这也是通常用的办法。但是问题又来了,通常来说,神经网络的损失函数具有很大的震荡幅度,直接拿来用是不可行的。
作者提出了一种基于序列的方法,使得训练的表现和损失函数的值呈正相关。对于目标任务 t,用矩阵 Wt来表示可迁移到 t 的源域任务的表现。矩阵中的元素 wij 就表示:在同一个分出来的测试集上,源域 si 迁移到 t,比 sj 迁移到 t 的表现好的百分比。比如 s1 到 t 要比 s2 到 t 好 15%。这个矩阵表示的是两两之间的比较,因此作者形象地把它叫做 tournament matrix(锦标赛矩阵)。 最后作者对得到的新矩阵进行了特征分解,则 si 到 t 的迁移表现就是第 i 个特征向量。把所有目标域 t 的特征向量组合起来就得到了一个相似度矩阵。这个矩阵是归一化过的。
这个方法不是作者发明的,是之前有人发明的,叫做 Analytic Hierarchy Process。
5.第四步:计算可迁移图
最后一步,我们要基于affinity matrix求得如何最有效地学习一组我们感兴趣的任务。我们可以这个问题想象成一个subgraph selection的问题:选择一些任务从零学习,剩下的任务用少量数据进行迁移学习,具体迁移学习的策略由subgraph中的edge来决定(对一条directed edge,起始点代表我们从零学习的一个任务,终点代表要进行迁移的目标任务)。基于此,我们可以通过解如下BIP最优化问题来得到最优解:
这个最优问题有三个限制条件:
- 如果我们选择了一个迁移,那么迁移的起始任务(可能为高阶起始集)和目标任务均要出现在subgraph中;
- 每个目标任务有且仅有一个迁移(我们将从零学习在途中定义为从自己到自己的迁移,即一条自己到自己的edge);
- 不超过监督预算。
结论
实验部分是本文的重点。作者收集的数据集共包含 26 个计算机视觉的通用任务。在这些任务上,作者进行源领域训练、单一迁移、高阶迁移,一共构建了大约 3000 个学习任务,一共需要47886 个 GPU 小时来进行计算。
实验所用的所有编码器都是相同的,都基于 ResNet-50,去掉了 pooling 层。所有的迁移网络用的都是包含 2 个卷积的网络。损失函数和解码器就相应地根据不同任务进行调整。调整方式可见文章。
作者在一部分数据上进行实验,把这部分数据进行了如下的划分:训练集 120k,验证集 16k,测试集 17k。主要进行了以下方面的实验:
目标网络的性能
作者首先比较了不迁移情况下,目标网络的性能,也就是方法部分中的第 1 步。对比两个最近的方法可以看出,文章的网络性能不错。
领域相似度情况
作者验证了根据构建出的相似度矩阵进行相似度挖掘的实验,对不同的任务都画出了迁移性能图。从图中就可以清楚地知道哪些任务是对目标任务的迁移效果好坏。 作者又进一步对这些结果进行了更好的图示。
新任务上的泛化能力
将一个任务作为目标任务,其他 25 个任务作为源领域任务,考察模型在新任务上的泛化能力。实现效果显示这种迁移会比当前一些最好的非迁移深度方法还要好。从中我们得出的结论是,如果能够选择好源域任务,那么通常来说迁移学习的表现都要比直接从目标领域训练要好。
模型的扩展性
另外,作者还在 MIT Place 和 ImageNet 两个大型图像数据集上测试了方法的可扩展性。并且根据迁移效果,构建了迁移树用于进一步分析迁移表现。
局限性
作者还在文章花费很多篇幅讨论了自己方法的局限性。主要有以下几点:
方法可能依赖于特定的数据和模型:尽管作者在不同的大型数据集上做了大量实验,作者依然担心,方法可能会依赖于特定的数据和网络。这么实诚的人不多了。
任务的通用性:作者只是在一些认为定义的任务上进行了实验。但有没有可能有更复杂更高级的任务?
任务空间限制:可能还需要更多的实验。迁移到非视觉和机器人任务。这是一个值得考虑的问题。
终身学习:此方法目前还是离线的。如何实现在线终身学习?
总结
本文最大的亮点是,构建了非常多的迁移学习任务,详尽地探索了不同任务之间进行迁移的效果,为以后的研究提供了宝贵的基础。方法比较朴素,但是实现完备,很值得我们学习。作者在探索之外,还专门提供了一个数据集,这种精神值得钦佩!我们在今后的研究中,也要学习这种实验精神,多做,少说,慢慢积累。 迁移到非视觉和机器人任务。这是一个值得考虑的问题。
终身学习。此方法目前还是离线的。如何实现在线终身学习?
参考文献
- Zamir A R, Sax A, Shen W, et al. Taskonomy: Disentangling Task Transfer Learning[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 3712-3722.