1.NVIDIA MPS介绍
MPS多进程服务(Multi-Process Scheduling)是CUDA应用程序编程接口(API)的替代二进制兼容实现。从Kepler的GP10架构开始,NVIDIA就引入了MPS(基于软件的多进程服务),这种技术在当时实际上是称为HyperQ ,允许多个 流(stream)或者CPU的进程同时向GPU发射Kernel函数,结合为一个单一应用程序的上下文在GPU上运行,从而实现更好的GPU利用率。在单个进程的任务处理,对GPU利用率不高的情况下是非常有用的。实际上,在Pascal架构出现之后的MPS可以认为是HyperQ的一种实现方式。
最近需要使用到MPS,但是发现网上资料不多,而且很杂乱,所以在此总结一下。官方文档链接
MPS作用:
多容器共享GPU会引发资源竞争和浪费的问题,不仅GPU利用率不高,也无法保证QoS。当使用NVIDIA MPS时,MPS Sever会通过一个CUDA Context管理GPU硬件资源,多个MPS Clients会将它们的任务通过MPS Server传入GPU,从而越过了硬件时间分片调度的限制,使得它们的CUDA kernels实现真正意义上的并行。特别地,Volta MPS可以兼容docker容器,并且支持执行资源配置(即每个Client context只能获取一定比例的threads),提高了多容器共享GPU的QoS。
增加GPU的利用率;
减少多个CUDA进程在GPU上的上下文空间。该空间主要是用于存储和调度资源;
减少GPU的上下文的切换。
但MPS实际上也是有一些使用限制的,比方它现在仅支持Linux操作系统,还要求GPU的运算能力必须大于3.5。
MPS实例
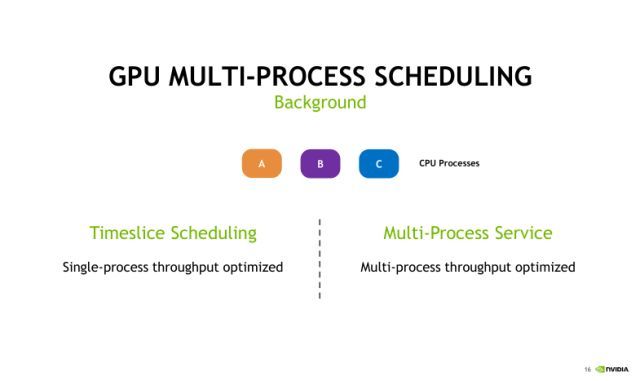
假设在CPU端有A、B、C三个进程,每个进程都要发射CUDA Kernel的任务到GPU上去,并且假设它们每一个独立的任务对GPU利用率都不高。
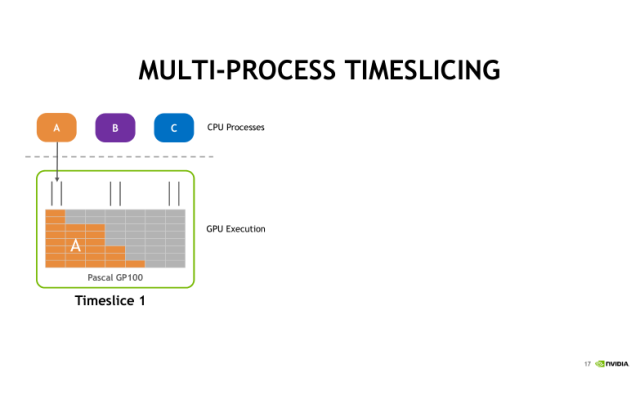
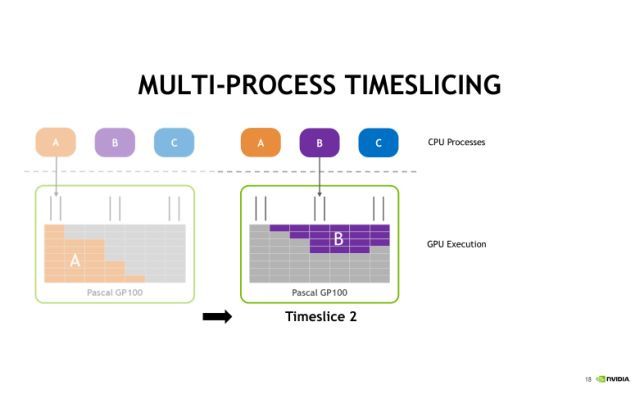

在不使用MPS服务的情况下,A、B、C三个进程实际上也可以同时把CUDA任务发射到GPU上去,但是默认采用时间片轮转调度的方式。首先第一个时间片,A任务被执行,接着第二个时间片,执行B任务,第三个时间片, C任务将被执行。时间片是依次进行轮转调度的,分别执行A、B、C中的任务。
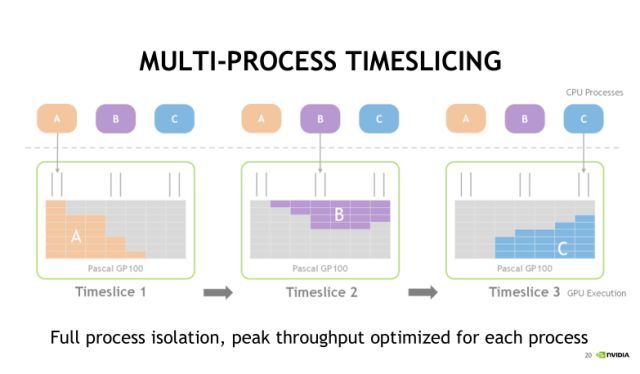
可以直观地看到, 在GPU中,每一个时刻只有一个任务在执行。这种情况下,CPU中的process(进程)发射的CUDA任务对GPU的利用率很低。
MPS与Hyper-Q区别
MPS与Hyper-Q的区别是:来自单个进程的CUDA任务与来自多个进程的CUDA任务之间存在差异。 Hyper-Q消除了来自单个进程的请求并发性的一些人为障碍。但是由于与Hyper-Q无关的CUDA行为,来自多个进程的请求仍然序列化。 MPS作为一个“漏斗”,用于从多个进程/级别收集CUDA任务,并将它们发布到GPU,就好像它们来自单个进程一样,以便Hyper-Q可以生效。
2.Pascal架构和Volta架构
我们常用的GTX 1080 ti和GP100是Pascal架构的,NVIDIA基于深度学习的任务特点推出了Volta架构的Tesla V100数据中心级显卡。我们简单低看一下两种架构的GPU区别。
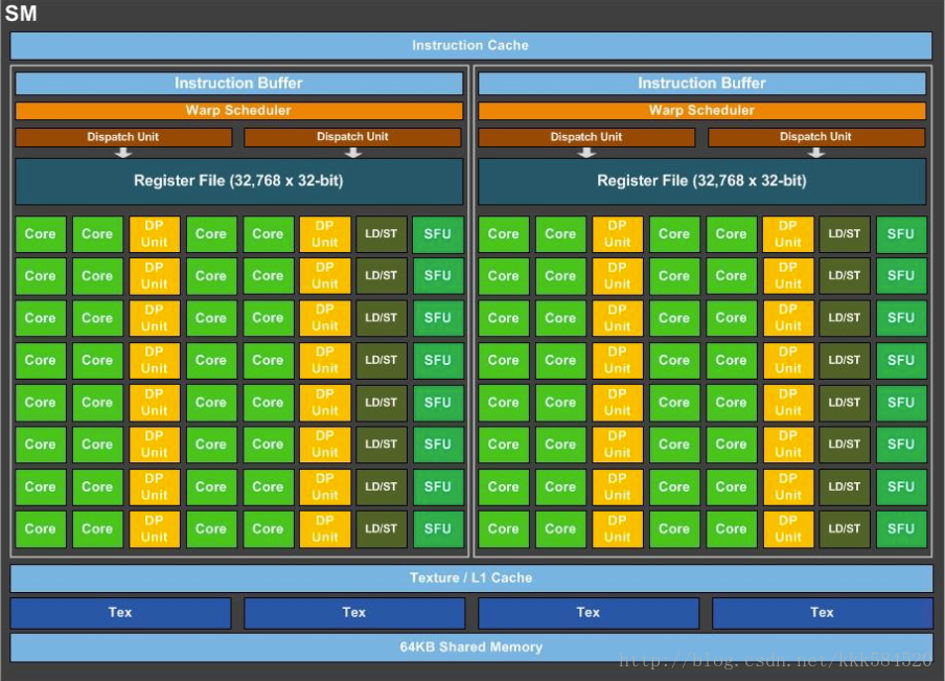
上图是Pascal SM 架构图,可以看到一个 GP100 SM 分成两个处理块,每块有32768 个 32 位寄存器 + 32 个单精度 CUDA 核心 + 16 个双精度 CUDA 核心 + 8 个特殊功能单元(SFU) + 8 个存取单元 + 一个指令缓冲区 + 一个 warp 调度器 + 两个分发单元。LD/ST加载存储单元,SFU为特殊功能单元,用来执行超越函数指令,如正弦函数。
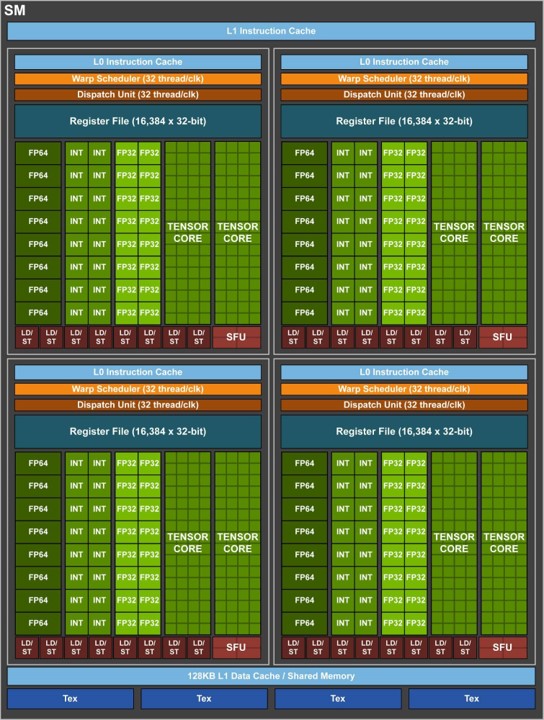
上图是Volta SM架构图,每个 SM 有 64 个 FP32 核、64 个 INT32 核、32 个 FP64 核与 8 个全新的 Tensor Core。新的 Tensor Core 是 Volta GV100 最重要的特征,有助于提高训练神经网络所需的性能。Tesla V100 的 Tensor Core 能够为训练、推理应用的提供 120 Tensor TFLOPS。相比于在 P100 FP 32 上,在 Tesla V100 上进行深度学习训练有 12 倍的峰值 TFLOPS 提升。而在深度学习推理能力上,相比于 P100 FP16 运算,有了 6 倍的提升。与前一代 Pascal GP100 GPU 类似,GV100 GPU 由多个图形处理集群(Graphics Processing Cluster,GPC)、纹理处理集群(Texture Processing Cluster,TPC)、流式多处理器(Streaming Multiprocessor,SM)以及内存控制器组成。一个完整的 GV100 GPU 由 6 个 GPC、84 个 Volta SM、42 个 TPC(每个 TPC 包含了 2 个 SM)和 8 个 512 位的内存控制器(共 4096 位)。
3.不同架构上的MPS实现
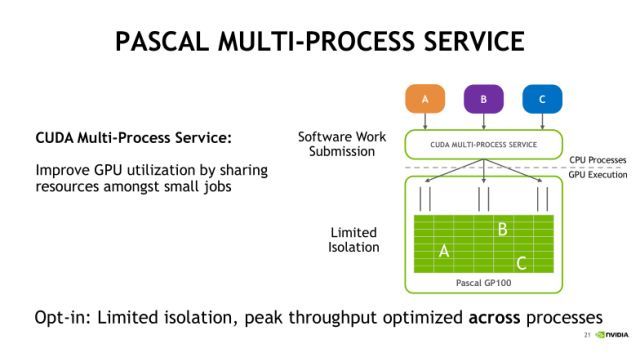
上图是基于Pascal架构的MPS服务对任务的处理情况。可以看到A、B、C三个进程分别提交各自的任务到MPS的服务端,并在服务端整合为一个统一的上下文,并将三个任务同时发射到GPU中执行,这就有效地提升了GPU的利用率。在Pascal架构下,MPS是最多可以支持16个进程或者说16个用户同时提交任务。
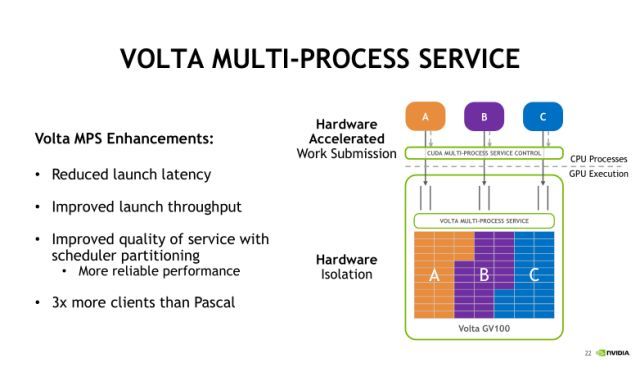
上图是Volta架构MPS的执行情况,Volta架构对MPS的实现做了改进,主要是基于硬件加速的方式来实现。此时不同的进程是可以直接穿过MPS服务器,提交任务到GPU的硬件,并且每个进程客户端有隔离的地址空间,这样可以进一步减少Launch(发射进程)时带来的延迟,也可以通过限制执行资源配置来提升服务质量。这里所说提升服务质量是指怎么样平衡多个process(进程)发射任务对计算和存储资源的占用情况。比如我们现在可以去设定每一个process上下文,最多可以使用多少个资源。Volta下的MPS服务最多可以允许同时48个Client(客户端)。
4.MPS基准测试
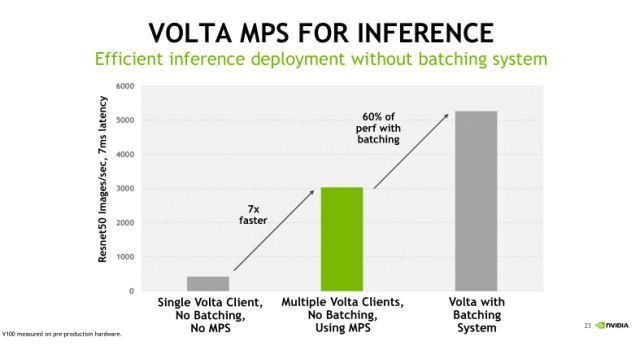
官方给出的一个benchmark(基准)测试。我们知道,对于单个任务占用GPU资源比较少的情形,MPS服务是非常有用的,比如在深度学习中做Inference(推理)应用。相比Training(训练),Inference对于计算和存储资源的要求比较小,这个时候会出现我们之前看到的情况,单一的Kernel任务是没法有效利用GPU的。从上面的benchmark可以看到图中最左侧灰色的柱状图,在不使用MPS的情况下,Inference的吞吐性能很小;而中间绿色的柱状图,使用MPS允许多个Client同时发射计算任务到GPU,此时GPU吞吐性能直接提升了七倍;最后一个柱状图表示,如果我们使用MPS,并结合Batching操作,吞吐性能还能继续再提升60%左右。由此可见,对于像Deep Learning的Inference这样的应用,MPS技术是可以有效地帮助我们优化GPU利用率以及程序的吞吐性能。
5.MPS的使用
MPS组成
MPS主要包括控制守护进程(MPS Control Daemo)、客户端运行时(Client Runtime)和服务进程(Server Process)。CUDA contexts可以通过MPS Server提交作业,这样就越过了硬件的时间切片调度的限制,实现多个进程在同一个GPU上并行执行。如果没有MPS,多个进程只是在同一个GPU上并发执行,即每个进程在一个时间分片里独享GPU。
默认情况下,GPU是没有开启MPS的,每个CUDA程序会创建自己的CUDA Context来管理GPU资源,并以时间分片的方式共享GPU。开启MPS后,在需要的时候,MPS control daemon会启动一个MPS Server,监听任务请求。
MPS执行过程
当CUDA首次在程序中初始化时,CUDA驱动程序将尝试连接到MPS控制守护进程。 如果连接尝试失败,程序继续运行,正常情况下没有MPS。 但是,如果连接尝试成功,则MPS控制守护程序将继续执行,以确保在与客户端连接之前启动的MPS服务器与连接客户端的用户标识相同。 MPS客户端然后继续连接到服务器。 MPS客户端,MPS控制守护程序和MPS服务器之间的所有通信都使用命名pipe道完成。默认情况下,命名pipe道被放置在/tmp/nvidia-mps/下
开启与关闭MPS
启动 mps-control
1 | export CUDA_VISIBLE_DEVICES=0 |
关闭mps-control
1 | echo quit | nvidia-cuda-mps-control |
注意以上两个命令需要管理员权限。
Volta MPS资源配置
执行资源配置的方法如下:
1 | nvidia-cuda-mps-control |
命令为每个MPS Client限制10%的threads。不是为每个Client预留专用资源,而是限制它们可以最多使用多少threads。默认情况下,每个Client可以获取所有threads(即100%)。
公平性
关闭MPS,多任务通过时间分片的调度方式共享GPU;开启MPS,多任务共享Server的CUDA Context。无论哪种情况,在所有任务所占显存总容量不超出GPU容量时,每个任务都能公平地获得GPU的threads。
6.MPS程序示例
示例来自stackoverflow
编写主程序
1 | $ cat t1034.cu |
编写开启MPS脚本
1 | $ cat start_as_root.bash |
编写执行程序
1 | $ cat mps_run |
编写关闭MPS脚本
1 | $ cat stop_as_root.bash |
运行MPS脚本
1 | $ ./mps_run |
运行主程序
1 | $ ./start_as_root.bash |
参考资料
- https://cloud.tencent.com/developer/article/1081424
- https://cloud.tencent.com/developer/article/1117712
- https://blog.csdn.net/kkk584520/article/details/53814067
- https://www.cnblogs.com/xingzifei/p/6136095.html
- https://blog.csdn.net/beckham999221/article/details/86644970
- https://blog.csdn.net/beckham999221/article/details/85257137